|
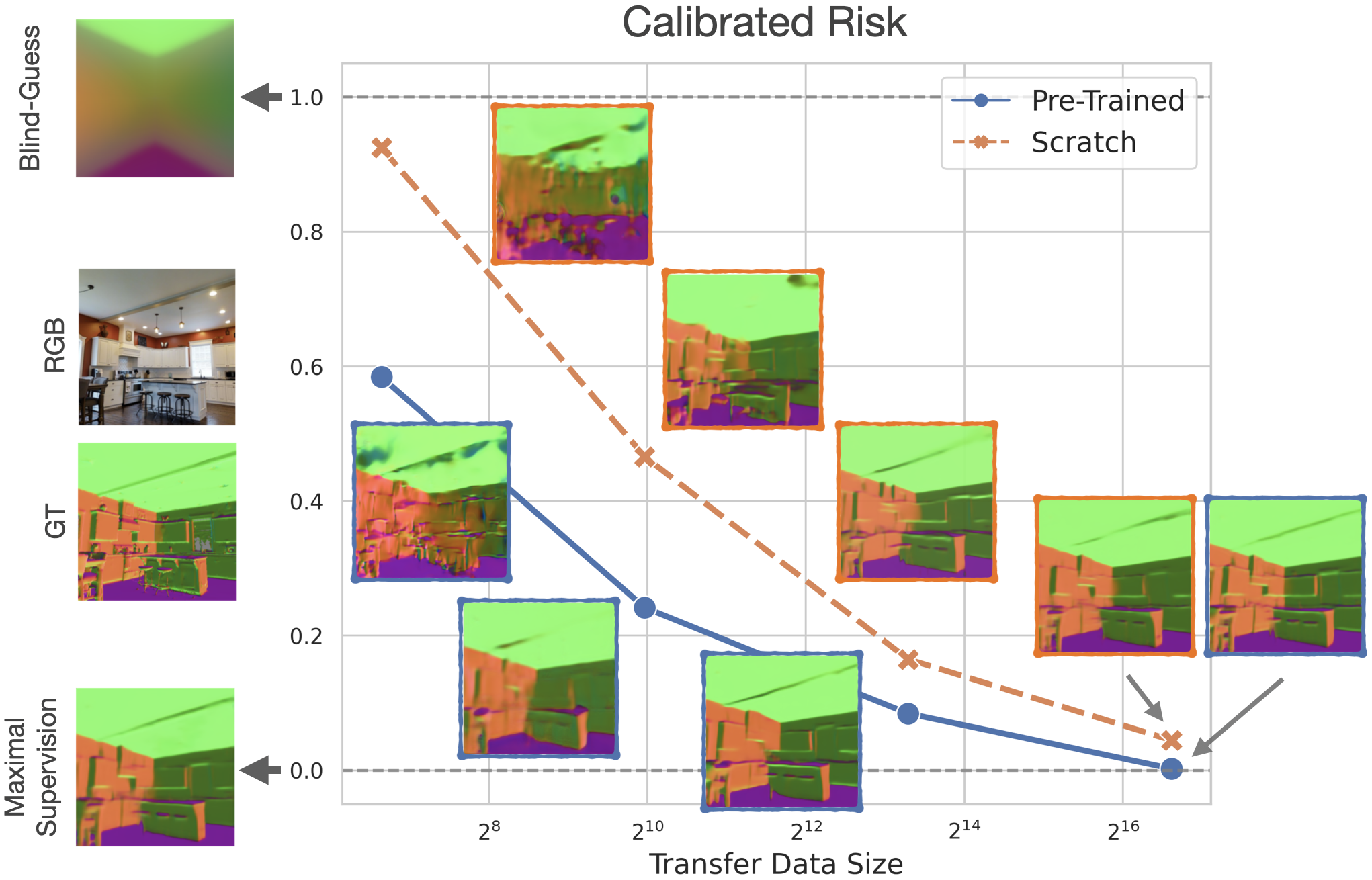
Transfer learning has witnessed remarkable progress in recent years, for example, with the introduction of augmentation-based contrastive self-supervised learning methods. While a number of large-scale empirical studies on the transfer performance of such models have been conducted, there is not yet an agreed-upon set of control baselines, evaluation practices, and metrics to report, often hindering a nuanced and calibrated understanding of the real efficacy of the methods. We propose an evaluation standard that aims to quantify and communicate transfer learning performance in an informative and accessible setup. This is done by baking a number of simple yet critical control baselines in the evaluation method, particularly the `blind-guess' (quantifying the dataset bias), `scratch-model' (quantifying the architectural contribution), and `maximal-supervision' (quantifying the upper-bound). To demonstrate how the proposed evaluation standard can be employed, we provide an example empirical study investigating a few basic questions about self-supervised learning. For example, using this standard, the study shows the effectiveness of existing self-supervised pre-training methods is skewed towards image classification tasks versus others, such as dense pixel-wise predictions.
|